搜索到
1893
篇与
的结果
-
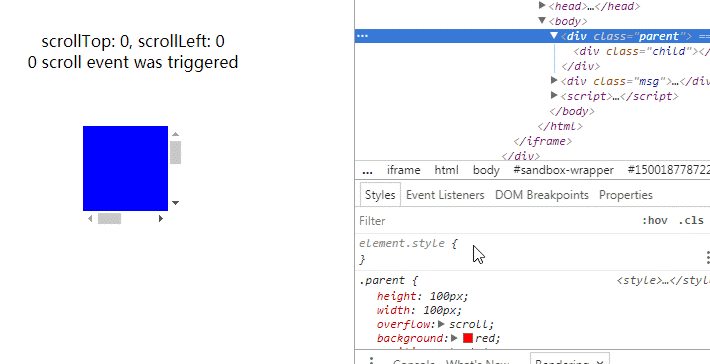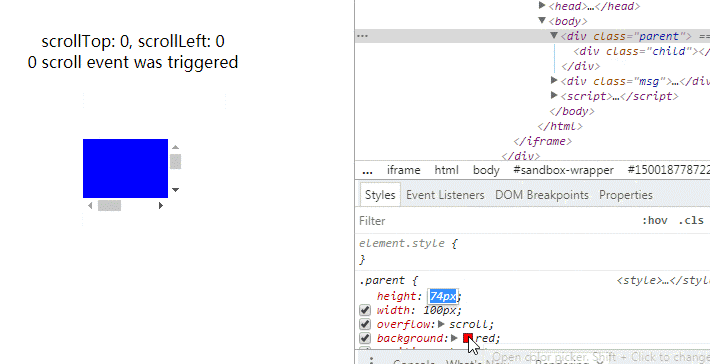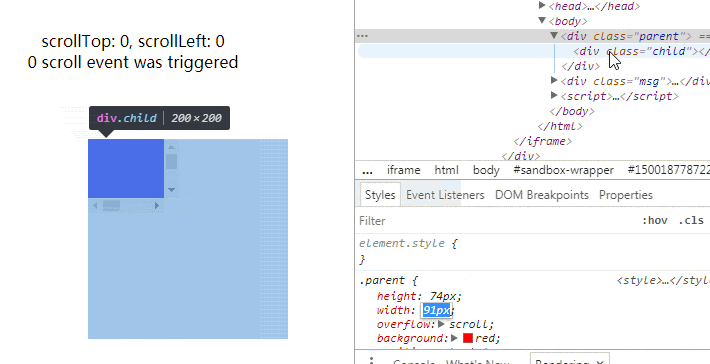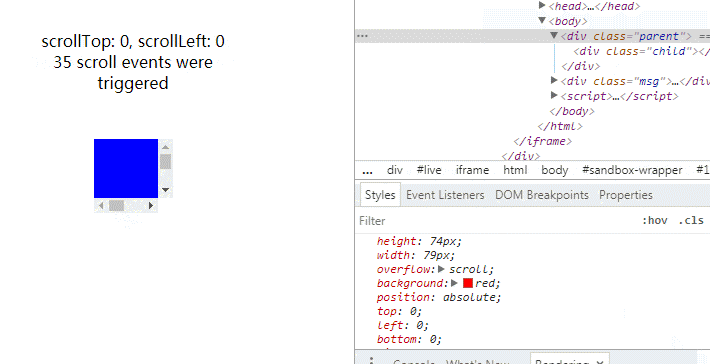
 巧妙监测元素尺寸变化 在往下读之前不妨先想一下,你会怎么实现?如何知道元素的尺寸发生变化了?相信很多人第一反应是 resize 事件,但这个只是 document view 变化才会触发。然后就是轮询,反复查询值变化了没有。开销不是一般的大,但像这样的库(比如这个七年前的)现在还有人用。最后便是这个,号称 event based 无性能问题,便去观摩了一番源码。代码本身没什么惊喜,所以本文不会像之前一样逐行逐块地分析,而是着重原理,对应这部分的源码。整体思路这个方法的主要思想是在被监测元素里包裹一个跟元素位置大小相同的隐藏块。隐藏块可以滚动,并有一个远远大于它的子元素。当被监测元素尺寸变化时期望能触发隐藏块的滚动事件。这个方法听起来很简单是不是,但如果你直接这么实现会发现时而行时而不行,问题就在于触发滚动事件的条件。如何计算滚动?这是我觉得这个话题值得写成文章的一个有趣点。我们理所当然地看待滚动,但有没有想过它是怎么计算的呢?发生滚动的时机有问题当然要去请教规范老师。第一步我们需要知道什么时候才会发生滚动,首先一个题外话,overflow 为 hidden 也是可以滚动的,另外一篇分析里也遇到过。在这里提到滚动事件发生的时机,但说得有点笼统Whenever an element gets scrolled (whether in response to user interaction or by an API)但从这段我们可以知道,每次发生滚动的时候,浏览器会先收集起来,在下次 event loop 到达时统一地处理。滚动的描述在这里:To scroll an element element to x,y optionally with a scroll behavior behavior (which is "auto" if omitted) means to: Let box be element’s associated scrolling box. If box has rightward overflow direction Let x be max(0, min(x, element scrolling area width - element padding edge width)). If box has leftward overflow direction Let x be min(0, max(x, element padding edge width - element scrolling area width)). If box has downward overflow direction Let y be max(0, min(y, element scrolling area height - element padding edge height)). If box has upward overflow direction Let y be min(0, max(y, element padding edge height - element scrolling area height)). Let position be the scroll position box would have by aligning scrolling area x-coordinate x with the left of box and aligning scrolling area y-coordinate y with the top of box. If position is the same as box’s current scroll position, and box does not have an ongoing smooth scroll, abort these steps. Perform a scroll of box to position, element as the associated element and behavior as the scroll behavior. 最后一步“perform a scroll”才会真正触发滚动事件。第五步便是问题关键,位置相同的时候,滚动事件不会发生。重排根据前面的整体思路,当被监测元素尺寸发生变化时,隐藏元素也跟着变化。于是引发了 Layout/Reflow 使到重新计算滚动位置 position。但这时也许你会发现 position 根本没有变化,如图一。 .parent { height: 100px; width: 100px; overflow: scroll; background: red; position: absolute; top: 0; left: 0; bottom: 0; right: 0; margin: auto; } .child { height: 200%; width: 200%; background: blue; } .msg { position: absolute; top: 370px; left: 50%; transform: translateX(-50%); text-align: center; } var parent = document.querySelector('.parent') var child = document.querySelector('.child') var msg1 = document.querySelector('.msg1') var msg2 = document.querySelector('.msg2') parent.scrollTop = 1000 parent.scrollLeft = 1000 var eventCount = 0 function log () { msg1.innerText = `scrollTop:${parent.scrollTop}, scrollLeft:${parent.scrollLeft}` msg2.innerText = `${eventCount}scroll event${eventCount > 1 ? 's were' : ' was'}triggered` } log() parent.addEventListener('scroll', () => { eventCount += 1 log() }) 为什么?上面的第二、三步有答案。一般来说,我们的设备都是上到下、左到右,所以属于右下方向溢出,对应上面的 2.1 和 3.1 公式。每次计算滚动距离都会跟可滚动的空间比较取最小值。因为子元素的尺寸是固定的,且远远大于容器,故两者的差非常大,所以最小值一直是 x 和 y,每次重排都会在同个位置,触发了上面的第五步。同时根据公式易得:当可滚动空间一开始不比 x 和 y 大,且随滚动不断变小时,就可以让 position 发生变化。于是,我们先让元素滚到最尽头,那么 x 和 y 达到了最大值。当容器尺寸变大时,因为子元素的尺寸是固定的,故 scrolling area 的大小不变,所以两者的差变小了,x 和 y 得到新的最小值,发生了滚动。见图二。/* ... */ .child { height: 200px; width: 200px; } /* ... */// ..... var msg2 = document.querySelector('.msg2') parent.scrollTop = 1000 parent.scrollLeft = 1000 var eventCount = 0 // ....初始的 1 个事件就是上面提到的 event loop 导致的。可以观察滚动发生,我们期望容器达到最大时 x 和 y 都没有达到最小值,所以子元素的大小须比容器最大值要大。动图同时也可观察到容器变小时没反应。按上面的公式也很容易知道,容器变小了,差值变大了,所以最小值还是 x 和 y,故不触发滚动。怎么办呢?物尽其用再看回公式,我们希望容器变小时,差值也变小。那么只能是让 scrolling area 也跟着变小了。如果子元素大小改为百分比行不?我们来证明一下。设容器宽度为 x1 或者 x2,其中 x2 > x1,子元素大小为 n * x1 或 n * x2,因我们不设 padding,则有n * x1 - x1 = 1 ↓ n >= 2故我们只需让子元素大小至少为 200% 就可以!见图三/* ... */ .child { height: 200%; width: 200%; } /* ... */// ..... var msg2 = document.querySelector('.msg2') parent.scrollTop = 1000 parent.scrollLeft = 1000 var eventCount = 0 // ....同时也说明百分比不能监测容器变大,因为 0 < n < 1 与 n >= 1 + 1/Max 矛盾,可自行证明。所以,结合两个方式就可以监测元素扩大与缩小变化。代码原理搞通之后代码就不难了,我这里另外重新实现了一遍,修改了隐藏块的创建方式以及加入 passive events 优化滚动。Demo 里拖动一个块改变大小另一个会同步变化,可以看到非常的流畅。
巧妙监测元素尺寸变化 在往下读之前不妨先想一下,你会怎么实现?如何知道元素的尺寸发生变化了?相信很多人第一反应是 resize 事件,但这个只是 document view 变化才会触发。然后就是轮询,反复查询值变化了没有。开销不是一般的大,但像这样的库(比如这个七年前的)现在还有人用。最后便是这个,号称 event based 无性能问题,便去观摩了一番源码。代码本身没什么惊喜,所以本文不会像之前一样逐行逐块地分析,而是着重原理,对应这部分的源码。整体思路这个方法的主要思想是在被监测元素里包裹一个跟元素位置大小相同的隐藏块。隐藏块可以滚动,并有一个远远大于它的子元素。当被监测元素尺寸变化时期望能触发隐藏块的滚动事件。这个方法听起来很简单是不是,但如果你直接这么实现会发现时而行时而不行,问题就在于触发滚动事件的条件。如何计算滚动?这是我觉得这个话题值得写成文章的一个有趣点。我们理所当然地看待滚动,但有没有想过它是怎么计算的呢?发生滚动的时机有问题当然要去请教规范老师。第一步我们需要知道什么时候才会发生滚动,首先一个题外话,overflow 为 hidden 也是可以滚动的,另外一篇分析里也遇到过。在这里提到滚动事件发生的时机,但说得有点笼统Whenever an element gets scrolled (whether in response to user interaction or by an API)但从这段我们可以知道,每次发生滚动的时候,浏览器会先收集起来,在下次 event loop 到达时统一地处理。滚动的描述在这里:To scroll an element element to x,y optionally with a scroll behavior behavior (which is "auto" if omitted) means to: Let box be element’s associated scrolling box. If box has rightward overflow direction Let x be max(0, min(x, element scrolling area width - element padding edge width)). If box has leftward overflow direction Let x be min(0, max(x, element padding edge width - element scrolling area width)). If box has downward overflow direction Let y be max(0, min(y, element scrolling area height - element padding edge height)). If box has upward overflow direction Let y be min(0, max(y, element padding edge height - element scrolling area height)). Let position be the scroll position box would have by aligning scrolling area x-coordinate x with the left of box and aligning scrolling area y-coordinate y with the top of box. If position is the same as box’s current scroll position, and box does not have an ongoing smooth scroll, abort these steps. Perform a scroll of box to position, element as the associated element and behavior as the scroll behavior. 最后一步“perform a scroll”才会真正触发滚动事件。第五步便是问题关键,位置相同的时候,滚动事件不会发生。重排根据前面的整体思路,当被监测元素尺寸发生变化时,隐藏元素也跟着变化。于是引发了 Layout/Reflow 使到重新计算滚动位置 position。但这时也许你会发现 position 根本没有变化,如图一。 .parent { height: 100px; width: 100px; overflow: scroll; background: red; position: absolute; top: 0; left: 0; bottom: 0; right: 0; margin: auto; } .child { height: 200%; width: 200%; background: blue; } .msg { position: absolute; top: 370px; left: 50%; transform: translateX(-50%); text-align: center; } var parent = document.querySelector('.parent') var child = document.querySelector('.child') var msg1 = document.querySelector('.msg1') var msg2 = document.querySelector('.msg2') parent.scrollTop = 1000 parent.scrollLeft = 1000 var eventCount = 0 function log () { msg1.innerText = `scrollTop:${parent.scrollTop}, scrollLeft:${parent.scrollLeft}` msg2.innerText = `${eventCount}scroll event${eventCount > 1 ? 's were' : ' was'}triggered` } log() parent.addEventListener('scroll', () => { eventCount += 1 log() }) 为什么?上面的第二、三步有答案。一般来说,我们的设备都是上到下、左到右,所以属于右下方向溢出,对应上面的 2.1 和 3.1 公式。每次计算滚动距离都会跟可滚动的空间比较取最小值。因为子元素的尺寸是固定的,且远远大于容器,故两者的差非常大,所以最小值一直是 x 和 y,每次重排都会在同个位置,触发了上面的第五步。同时根据公式易得:当可滚动空间一开始不比 x 和 y 大,且随滚动不断变小时,就可以让 position 发生变化。于是,我们先让元素滚到最尽头,那么 x 和 y 达到了最大值。当容器尺寸变大时,因为子元素的尺寸是固定的,故 scrolling area 的大小不变,所以两者的差变小了,x 和 y 得到新的最小值,发生了滚动。见图二。/* ... */ .child { height: 200px; width: 200px; } /* ... */// ..... var msg2 = document.querySelector('.msg2') parent.scrollTop = 1000 parent.scrollLeft = 1000 var eventCount = 0 // ....初始的 1 个事件就是上面提到的 event loop 导致的。可以观察滚动发生,我们期望容器达到最大时 x 和 y 都没有达到最小值,所以子元素的大小须比容器最大值要大。动图同时也可观察到容器变小时没反应。按上面的公式也很容易知道,容器变小了,差值变大了,所以最小值还是 x 和 y,故不触发滚动。怎么办呢?物尽其用再看回公式,我们希望容器变小时,差值也变小。那么只能是让 scrolling area 也跟着变小了。如果子元素大小改为百分比行不?我们来证明一下。设容器宽度为 x1 或者 x2,其中 x2 > x1,子元素大小为 n * x1 或 n * x2,因我们不设 padding,则有n * x1 - x1 = 1 ↓ n >= 2故我们只需让子元素大小至少为 200% 就可以!见图三/* ... */ .child { height: 200%; width: 200%; } /* ... */// ..... var msg2 = document.querySelector('.msg2') parent.scrollTop = 1000 parent.scrollLeft = 1000 var eventCount = 0 // ....同时也说明百分比不能监测容器变大,因为 0 < n < 1 与 n >= 1 + 1/Max 矛盾,可自行证明。所以,结合两个方式就可以监测元素扩大与缩小变化。代码原理搞通之后代码就不难了,我这里另外重新实现了一遍,修改了隐藏块的创建方式以及加入 passive events 优化滚动。Demo 里拖动一个块改变大小另一个会同步变化,可以看到非常的流畅。 -
prototype 与 __proto__ 的爱恨情仇 经历了上次的《JavaScript This 的六道坎》 发现编故事有点上瘾,而且记忆效果也不错哈哈,今天继续唠叨一下 prototype 与 __proto__ 的爱恨情仇。先理解两者的一个本质区别,prototype 是函数独有的,是人为设定的;__proto__ 是所有对象都有的,是继承的。然后来看一个两个神的故事:首先在 ECMAScript 星球,万物起源于 the Engineers,哦不,是一个叫 %ObjectPrototype% 的 intrinsic object,也就是 Object.prototype。它是万物的尽头,继承于虚无, Object.prototype.__proto__ 为 null。接着由其衍生出第二神,另外一个 intrinsic object %FunctionPrototype%,也就是 Function.prototype。于是有Function.prototype.__proto__ === Object.prototype // trueFunction.prototype 本身也是个函数对象,这是为了兼容 ES5。也估计是让人引起误解的源头。但两者还是不同的,这是个特殊的函数对象,它忽略参数总是返回 undefined,且没有 [[Construct]] 内部方法。搞清楚了这两个 Ancient Gods 接下来就很容易了,相信也听过“函数在 JS 里是一等公民”这类的说法,其实是因为它们都是 %FunctionPrototype% 的子民(这里不用 Function.prototype 是为了避免混淆,记得 prototype 是人为设定的),包括 Function 本身。所以你可以看到,Object、Function、String、Number、Boolean 等等等的 __proto__ 都是 Function.prototype。所以接下来的问题就更容易了,比如 Object instanceof Object。前面我们知道 Object.__proto__ 是 %FunctionPrototype%,而它的 __proto__ 是万物之源 %ObjectPrototype%,恰好也是 Object.prototype,所以就是 true 啦。其它的也是同理,举一反三很简单了。
-
检测 DOM 结点插入 闲逛 Github 时碰见一个叫 SentinelJS 的库,声称能检测 DOM 结点的插入,顿时引起了好奇。因为以前无聊时也想过一下,没什么头绪,便不了了之。当时第一反应是该不会用轮询吧(比这粗暴的实现也不是没见过)。但看到 682 bytes (minified + gzipped) 大小时感觉一定又是用了什么奇淫怪巧,个人对这种东西很感兴趣(见另一篇《巧妙监测元素尺寸变化》),便顺便看了看源码,很短,但一看到 animation 时便拍大腿了!通过检测 animationstart 事件来检测插入,机智!代码很短,就是维护了一个事件队列。核心在 onFn 和 offFn 上。后者同理,便主要看 onFn 的实现。/** * Add watcher. * @param {array} cssSelectors - List of CSS selector strings * @param {Function} callback - The callback function */ function onFn(cssSelectors, callback, extraAnimations) { if (!callback) return; // initialize animationstart event listener if (!isInitialized) init(); // listify argument cssSelectors = Array.isArray(cssSelectors) ? cssSelectors : [cssSelectors]; // add css rules and cache callbacks cssSelectors.map(function(selector) { var animId = selectorToAnimationMap[selector]; if (!animId) { // add new CSS listener var css, i; animId = 'sentinel-' + Math.random().toString(16).slice(2); // add keyframe rule css = '@keyframes ' + animId + '{from{transform:none;}to{transform:none;}}'; i = styleSheet.cssRules.length; styleSheet.insertRule(css, i); styleSheet.cssRules[i]._id = selector; // add selector animation rule css = selector + '{animation-duration:0.0001s;animation-name:' + animId; if (extraAnimations) css += ',' + extraAnimations; css += ';}'; i += 1; styleSheet.insertRule(css, i); styleSheet.cssRules[i]._id = selector; // add to map selectorToAnimationMap[selector] = animId; } // add to callbacks var x = animationCallbacks[animId] = animationCallbacks[animId] || []; x.push(callback); }); }先生成一个随机的带前缀的 animId 来区分每个事件。animId = 'sentinel-' + Math.random().toString(16).slice(2);styleSheet 为一个事先挂载的 元素,所有的 animation 样式都会插入到这里。插入 @keyframes 之后在这条规则上面以选择器做了一个私有的标记 _id,为了在移除事件的时候找到这条规则。// add keyframe rule css = '@keyframes ' + animId + '{from{transform:none;}to{transform:none;}}'; i = styleSheet.cssRules.length; styleSheet.insertRule(css, i); styleSheet.cssRules[i]._id = selector;接下来再插入一个持续 0.0001s 的动画,监听搞定。接下来初始化的时候在 document 上监听 animationstart 事件:doc.addEventListener(event, animationStartHandler, true);通过事件的 animationName 来匹配 animId,成功则取消其它监听这个事件的回调。/** * Animation start handler * @param {Event} ev - The DOM event */ function animationStartHandler(ev) { var callbacks = animationCallbacks[ev.animationName] || [], l = callbacks.length; // exit if a callback hasn't been registered if (!l) return; // stop other callbacks from firing ev.stopImmediatePropagation(); // iterate through callbacks for (var i=0; i
-
React Native 搭配 MobX 使用心得 MobX 是一款十分优秀的状态管理库,不但书写简洁还非常高效。当然这是我在使用之后才体会到的,当初试水上车的主要原因是响应式,考虑到可能会更符合 Vue 过来的思考方式。然而其实两者除了响应式以外并没有什么相似之处:joy:。在使用过程中走了不少弯路,一部分是因为当时扫两眼文档就动手,对 MobX 机制理解得不够;其它原因是 MobX 终究只是一个库,会受限于 React 机制,以及与其它非 MobX 管理组件的兼容问题。当中很多情况在文档已经给出了说明(这里和这里),我根据自己遇到的再做一番总结。与非响应式组件兼容问题与非响应式的组件一起工作时,MobX 有时需要为它们提供一份非响应式的数据副本,以免 observable 被其它组件修改。observable.ref使用 React Navigation 导航时,如果要交由 MobX 管理,则需要手动配置导航状态栈,此时用 @observable.ref “浅观察”可避免状态被 React Navigation 修改时触发 MobX 警告。当 Navigator 接受 navigation props 时代表导航状态为手动管理。import { addNavigationHelpers, StackNavigator } from 'react-navigation' import { observable, action } from 'mobx' import { Provider, observer } from 'mobx-react' import AppComp from './AppComp' const AppNavigator = StackNavigator({ App: { screen: AppComp }, // ... }, { initialRouteName: 'App', headerMode: 'none' }) @observer export default class AppNavigation extends Component { @observable.ref navigationState = { index: 0, routes: [ { key: 'App', routeName: 'App' } ], } @action.bound dispatchNavigation = (action, stackNavState = true) => { const previousNavState = stackNavState ? this.navigationState : null this.navigationState = this.AppNavigator.router.getStateForAction(action, previousNavState) return this.navigationState } render () { return ( ) } }observable.shallowArray() 与 observable.shallowMap()MobX 还提供其它方便的数据结构来存放非响应式数据。比如使用 SectionList 的时候,我们要为其提供数据用于生成列表,由于 Native 官方的实现跟 MobX 不兼容,这个数据不能是响应式的,不然 MobX 会报一堆警告。MobX 有个 mobx.toJS() 方法可以导出非响应式副本;如果结构不相同还可以使用 @computed 自动生成符合的数据。但这两个方法每次添加项目都要全部遍历一遍,可能会存在性能问题。这时其实可以维护一个 observable.shallowArray,里面只放 key 数据,只用于生成列表(像骨架一样)。传给 SectionList 的 sections props 时 slice 数组复制副本(shallowArray 里的数据非响应式,所以只需浅复制,复杂度远小于上面两种方式)。然后 store 维护一个 observable.map 来存放每个项的数据,在项(item)组件中 inject store 进去,再利用 key 从 map 中获取数据来填充。通过 shallowArray 可以让 MobX 识别列表长度变化自动更新列表,利用 map 维护项数据可以使每个项保持响应式却互不影响,对长列表优化效果很明显。// store comp class MyStore { @observable sections = observable.shallowArray() @observable itemData = observable.map() @action.bound appendSection (section) { const data = [] section.items.forEach(action(item => { this.itemData.set(item.id, item) data.push({key: item.id}) })) this.sections.push({ key: section.id, data }) } }// MyList comp import { SectionList } from 'react-native' @inject('myStore') @observer class MyList extends React.Component { _renderItem = ({item}) => render () { return ( ) } }// SectionItem comp @inject('myStore') @observer class SectionItem extends React.Component { render () { const {myStore, id} = this.props const itemData = myStore.itemData.get(id) return ( {itemData.title} ) } }computed利用 @computed 缓存数据可以做一些优化。比如有一个响应式的数组 arr,一个组件要根据 arr 是否为空更新。如果直接访问 arr.length,那么只要数组长度发生变化,这个组件都要 render 一遍。此时利用 computed 生成,组件只需要判断 isArrEmpty 就可以减少不必要的更新:@computed get isArrEmpty () { return this.arr.length
-
获取选择文本所在的段落和句子 最近收到一个 issue 期望能在划词的时候同时保存单词的上下文和来源网址。这个功能其实很久之前就想过,但感觉不好实现一直拖延没做。真做完发现其实并不复杂,但有些小坑。完整代码已作为单独项目发布 get-selection-more,对原理感兴趣欢迎继续往下阅读。获取选择文本通过 window.getSelection() 即可获得一个 Selection 对象,再利用 .toString() 即可获得选择的文本。火狐坑在 Firefox 中,input 和 textarea 里的选词是不能通过 window.getSelection 获取的,只能通过 document.activeElement。锚节点与焦节点在 Selection 对象中还保存了两个重要信息,anchorNode 和 focusNode,分别代表选择产生那一刻的节点和选择结束时的节点,而 anchorOffset 和 focusOffset 则保存了选择在这两个节点里的偏移值。这时你可能马上就想到第一个方案:这不就好办了么,有了首尾节点和偏移,就可以获取句子的头部和尾部,再把选择文本作为中间,整个句子不就出来了么。当然不会这么简单哈😜。跨元素坑一般情况下,anchorNode 和 focusNode 都是 Text 节点(而且因为这里处理的是文本,所以其它情况也会直接忽略),可以考虑这种情况:Saladict is awesome!如果选择的是“awesome”,那么 anchorNode 和 focusNode 都是 is awesome!,所以取不到前面的 “Saladict”。另外还有嵌套的情况,也是同样的问题。Saladict is awesome!所以我们还需要遍历兄弟和父节点来获取完整的句子。反向选坑通过开始和结束节点来计算有个非常棘手的问题,如果用户是反方向选的词,那么开始节点会在结束节点的后方,我们需要反过来拼接。但如何知道是反方向呢?我们只能通过偏移值以及计算元素位置来判断,这就有点麻烦了。可以看到,通过开始结束节点不好计算,我们再看看有什么可用的属性。Range注意到 Selection 对象中还有一个 getRangeAt 方法。这个方法可以获取一个 Range 对象。Range 装的是文档片段,可以包含文本节点中的一部分。我们通过 Range.startContainer 和 Range.endContainer 可以获得 range 开始和结束的节点,通过 Range.startOffset 和 Range.endOffset 获得 range 在节点的偏移值。这里的前后节点不会受用户选词方向影响,所以我们无需再做判断。获取段落拿到选词范围后我们还是得遍历找到前后的段落。于是接下便是解决遍历边界的问题了。遍历到什么地方为止呢?我的判断标准是:跳过 inline-level 元素,遇到 block-level 元素为止。而判断一个元素是 inline-level 还是 block-level 最准确的方式应该是用 window.getComputedStyle()。但我认为这么做太重了,也不需要严格的准确性,所以用了常见的 inline 标签来判断。function isInlineNode(node?: Node | null): node is Node { if (!node) { return false } switch (node.nodeType) { case Node.TEXT_NODE: case Node.COMMENT_NODE: case Node.CDATA_SECTION_NODE: return true case Node.ELEMENT_NODE: { switch ((node as HTMLElement).tagName) { case 'A': case 'ABBR': case 'B': case 'BDI': case 'BDO': case 'BR': case 'CITE': case 'CODE': case 'DATA': case 'DFN': case 'EM': case 'I': case 'KBD': case 'MARK': case 'Q': case 'RP': case 'RT': case 'RTC': case 'RUBY': case 'S': case 'SAMP': case 'SMALL': case 'SPAN': case 'STRONG': case 'SUB': case 'SUP': case 'TIME': case 'U': case 'VAR': case 'WBR': return true } } } return false }获得句子获得选词所在句子我们需要在获取选词前后段落合并前通过正则匹配出句子在选词的前后部分。点号坑我们通过标点符号来判断一个句子结束的位置。这里需要注意 a.b 在编程的文章中十分常见,所以我们在这里不看作是句子的结束。// match head a.b is ok chars that ends a sentence const sentenceHeadTester = /((\.(?![ .]))|[^.?!。?!…\r\n])+$/ // match tail for "..." const tailMatch = /^((\.(?![\s.?!。?!…]))|[^.?!。?!…])*([.?!。?!…]){0,3}/回溯坑如果通过正则匹配前半部分,这里有个严重的性能问题。因为正则只能左往右匹配,随着段落前半部分的长度增加,匹配不成功回溯的复杂度也在增加。遇上非常长的段落(如一些滥用标签的网站)性能损耗甚至肉眼可见。故我们只好手动从右往左遍历一个个地匹配:function extractSentenceHead(leadingText: string): string { // split regexp to prevent backtracking if (leadingText) { const puncTester = /[.?!。?!…]/ /** meaningful char after dot "." */ const charTester = /[^\s.?!。?!…]/ for (let i = leadingText.length - 1; i >= 0; i--) { const c = leadingText[i] if (puncTester.test(c)) { if (c === '.' && charTester.test(leadingText[i + 1])) { // a.b is allowed continue } return leadingText.slice(i + 1) } } } return leadingText }最后获取前后部分之后只需简单拼接即可得到完整的上下文。可以看到当中还是有不少小坑,所以不建议再造轮子, get-selection-more 经过 Chrome 和 Firefox 测试,相对更靠谱些。